
What if we could make language models think more like humans? Instead of writing one word at a time, what if they could sketch out their thoughts first, and gradually refine them?
This is exactly what Large Language Diffusion Models (LLaDA) introduces: a different approach to current text generation used in Large Language Models (LLMs). Unlike traditional autoregressive models (ARMs), which predict text sequentially, left to right, LLaDA leverages a diffusion-like process to generate text. Instead of generating tokens sequentially, it progressively refines masked text until it forms a coherent response.
In this article, we will dive into how LLaDA works, why it matters, and how it could shape the next generation of LLMs.
I hope you enjoy the article!
To appreciate the innovation that LLaDA represents, we first need to understand how current large language models (LLMs) operate. Modern LLMs follow a two-step training process that has become an industry standard:
Note that current LLMs often use RLHF as well to further refine the weights of the model, but this is not used by LLaDA so we will skip this step here.
These models, primarily based on the Transformer architecture, generate text one token at a time using next-token prediction.
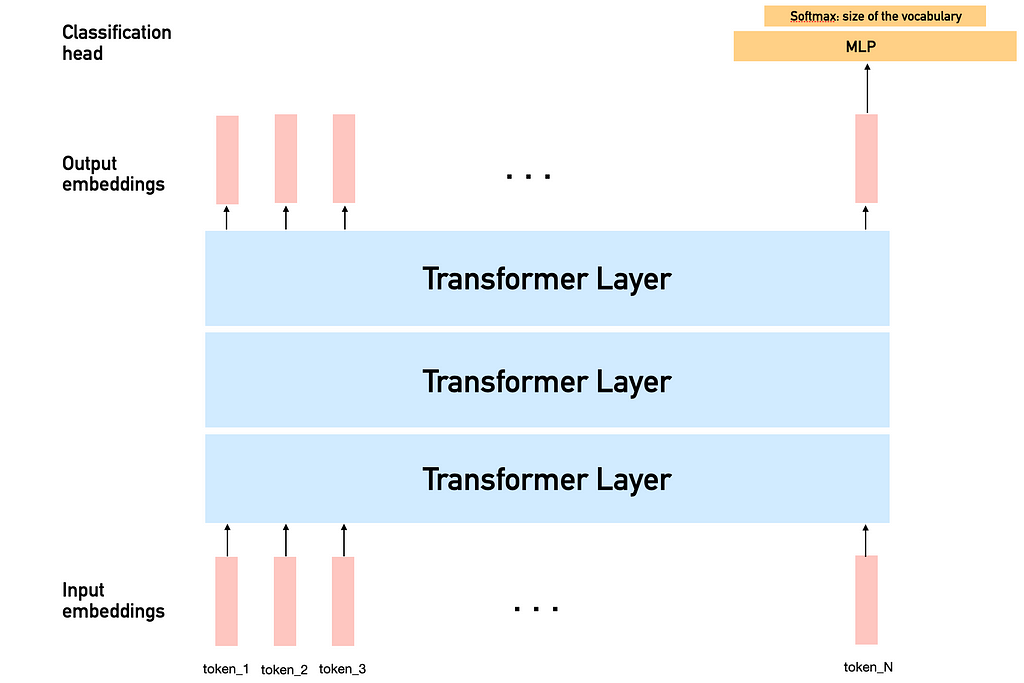
Here is a simplified illustration of how data passes through such a model. Each token is embedded into a vector and is transformed through successive transformer layers. In current LLMs (LLaMA, ChatGPT, DeepSeek, etc), a classification head is used only on the last token embedding to predict the next token in the sequence.
This works thanks to the concept of masked self-attention: each token attends to all the tokens that come before it. We will see later how LLaDA can get rid of the mask in its attention layers.
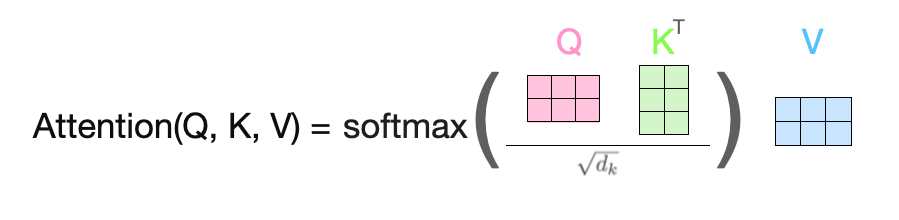
If you want to learn more about Transformers, check out my Medium article below:
Transformers: How Do They Transform Your Data?
While this approach has led to impressive results, it also comes with significant limitations, some of which have motivated the development of LLaDA.
Current LLMs face several critical challenges:
Imagine having to write a novel where you can only think about one word at a time, and for each word, you need to reread everything you’ve written so far. This is essentially how current LLMs operate — they predict one token at a time, requiring a complete processing of the previous sequence for each new token. Even with optimization techniques like KV caching, this process is quite computationally expensive and time-consuming.
Traditional autoregressive models (ARMs) are like writers who could never look ahead or revise what they’ve written so far. They can only predict future tokens based on past ones, which limits their ability to reason about relationships between different parts of the text. As humans, we often have a general idea of what we want to say before writing it down, current LLMs lack this capability in some sense.
Existing models require enormous amounts of training data to achieve good performance, making them resource-intensive to develop and potentially limiting their applicability in specialized domains with limited data availability.
LLaDA introduces a fundamentally different approach to language generation by replacing traditional autoregression with a “diffusion-based” process (we will dive later into why this is called “diffusion”).
Let’s understand how this works, step by step, starting with pre-training.
Remember that we don’t need any “labeled” data during the pre-training phase. The objective is to feed a very large amount of raw text data into the model. For each text sequence, we do the following:
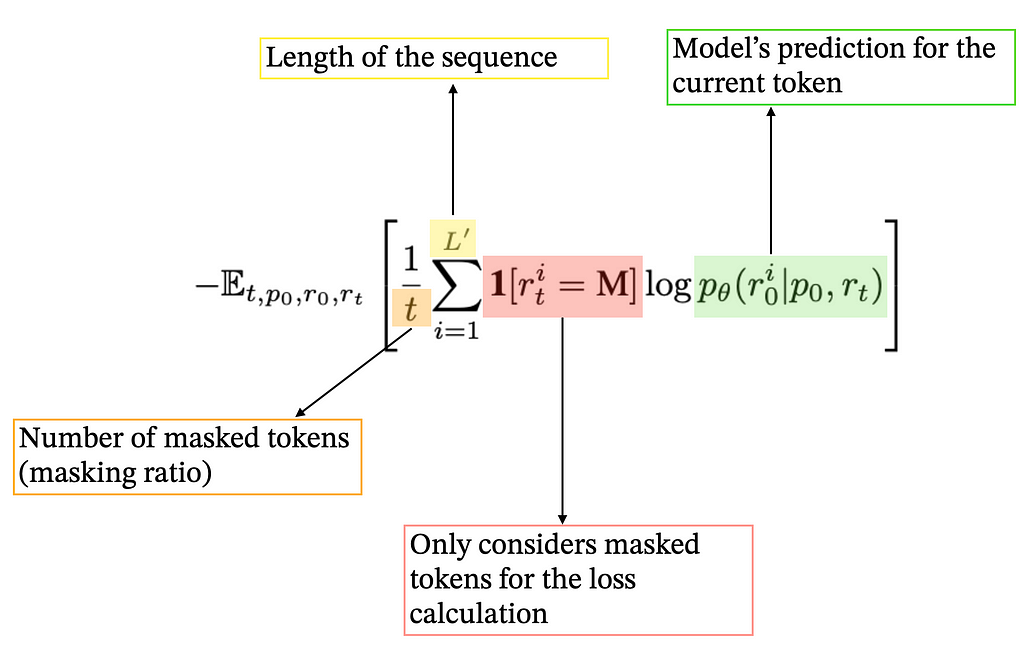
5. And… we repeat this procedure for billions or trillions of text sequences.
Note, that unlike ARMs, LLaDA can fully utilize bidirectional dependencies in the text: it doesn’t require masking in attention layers anymore. However, this can come at an increased computational cost.
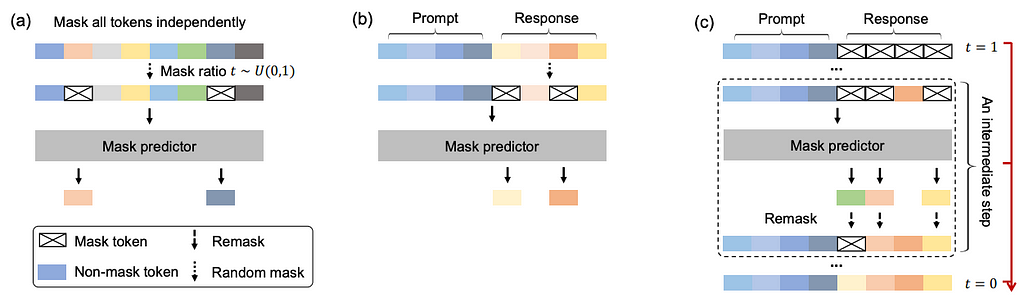
Hopefully, you can see how the training phase itself (the flow of the data into the model) is very similar to any other LLMs. We simply predict randomly masked tokens instead of predicting what comes next.
For auto-regressive models, SFT is very similar to pre-training, except that we have pairs of (prompt, response) and want to generate the response when giving the prompt as input.
This is exactly the same concept for LLaDA! Mimicking the pre-training process: we simply pass the prompt and the response, mask random tokens from the response only, and feed the full sequence into the model, which will predict missing tokens from the response.
Innovation is where LLaDA gets more interesting, and truly utilizes the “diffusion” paradigm.
Until now, we always randomly masked some text as input and asked the model to predict these tokens. But during inference, we only have access to the prompt and we need to generate the entire response. You might think (and it’s not wrong), that the model has seen examples where the masking rate was very high (potentially 1) during SFT, and it had to learn, somehow, how to generate a full response from a prompt.
However, generating the full response at once during inference will likely produce very poor results because the model lacks information. Instead, we need a method to progressively refine predictions, and that’s where the key idea of ‘remasking’ comes in.
Here is how it works, at each step of the text generation process:
You can see that, interestingly, we have much more control over the generation process compared to ARMs: we could choose to remask 0 tokens (only one generation step), or we could decide to keep only the best token every time (as many steps as tokens in the response). Obviously, there is a trade-off here between the quality of the predictions and inference time.
Let’s illustrate that with a simple example (in that case, I choose to keep the best 2 tokens at every step)
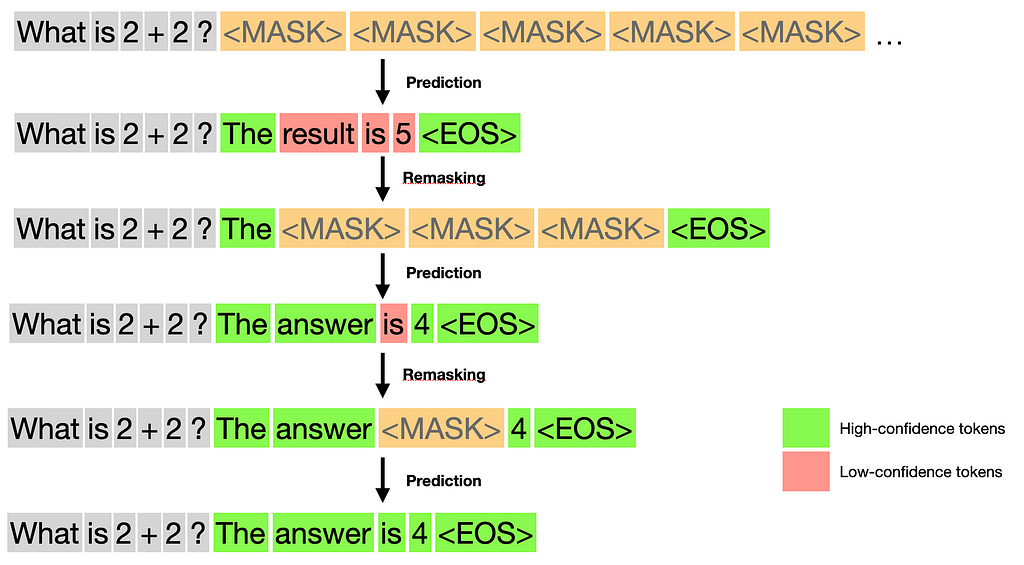
Note, in practice, the remasking step would work as follows. Instead of remasking a fixed number of tokens, we would remask a proportion of s/t tokens over time, from t=1 down to 0, where s is in [0, t]. In particular, this means we remask fewer and fewer tokens as the number of generation steps increases.
Example: if we want N sampling steps (so N discrete steps from t=1 down to t=1/N with steps of 1/N), taking s = (t-1/N) is a good choice, and ensures that s=0 at the end of the process.
The image below summarizes the 3 steps described above. “Mask predictor” simply denotes the LLM (LLaDA), predicting masked tokens.
Another clever idea developed in LLaDA is to combine diffusion with traditional autoregressive generation to use the best of both worlds! This is called semi-autoregressive diffusion.
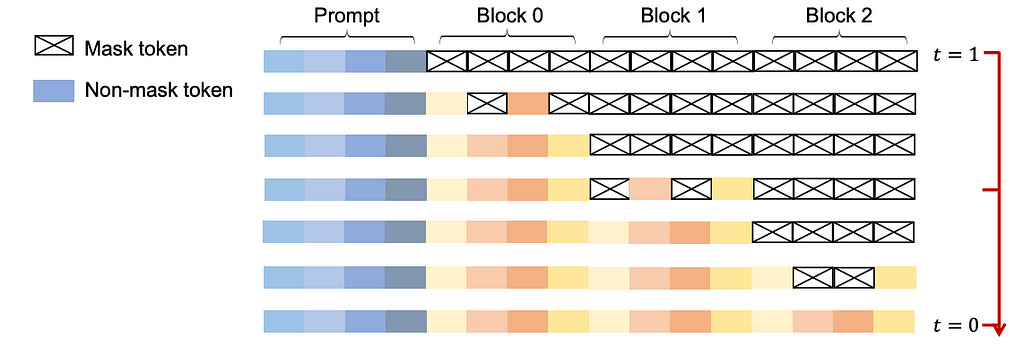
This is a hybrid approach: we probably lose some of the “backward” generation and parallelization capabilities of the model, but we better “guide” the model towards the final output.
I think this is a very interesting idea because it depends a lot on a hyperparameter (the number of blocks), that can be tuned. I imagine different tasks might benefit more from the backward generation process, while others might benefit more from the more “guided” generation from left to right (more on that in the last paragraph).
I think it’s important to briefly explain where this term actually comes from. It reflects a similarity with image diffusion models (like Dall-E), which have been very popular for image generation tasks.
In image diffusion, a model first adds noise to an image until it’s unrecognizable, then learns to reconstruct it step by step. LLaDA applies this idea to text by masking tokens instead of adding noise, and then progressively unmasking them to generate coherent language. In the context of image generation, the masking step is often called “noise scheduling”, and the reverse (remasking) is the “denoising” step.

You can also see LLaDA as some type of discrete (non-continuous) diffusion model: we don’t add noise to tokens, but we “deactivate” some tokens by masking them, and the model learns how to unmask a portion of them.
Let’s go through a few of the interesting results of LLaDA.
You can find all the results in the paper. I chose to focus on what I find the most interesting here.
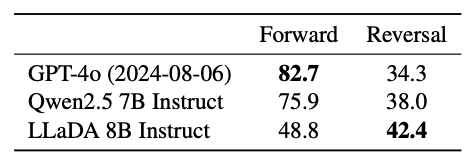
LLaDA is not just an experimental alternative to ARMs: it shows real advantages in efficiency, structured reasoning, and bidirectional text generation.
I think LLaDA is a promising approach to language generation. Its ability to generate multiple tokens in parallel while maintaining global coherence could definitely lead to more efficient training, better reasoning, and improved context understanding with fewer computational resources.
Beyond efficiency, I think LLaDA also brings a lot of flexibility. By adjusting parameters like the number of blocks generated, and the number of generation steps, it can better adapt to different tasks and constraints, making it a versatile tool for various language modeling needs, and allowing more human control. Diffusion models could also play an important role in pro-active AI and agentic systems by being able to reason more holistically.
As research into diffusion-based language models advances, LLaDA could become a useful step toward more natural and efficient language models. While it’s still early, I believe this shift from sequential to parallel generation is an interesting direction for AI development.
Thanks for reading!
Check out my previous articles:
<hr><p>LLaDA Explained: How Diffusion Could Revolutionize Language Models was originally published in Data Science Collective on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>